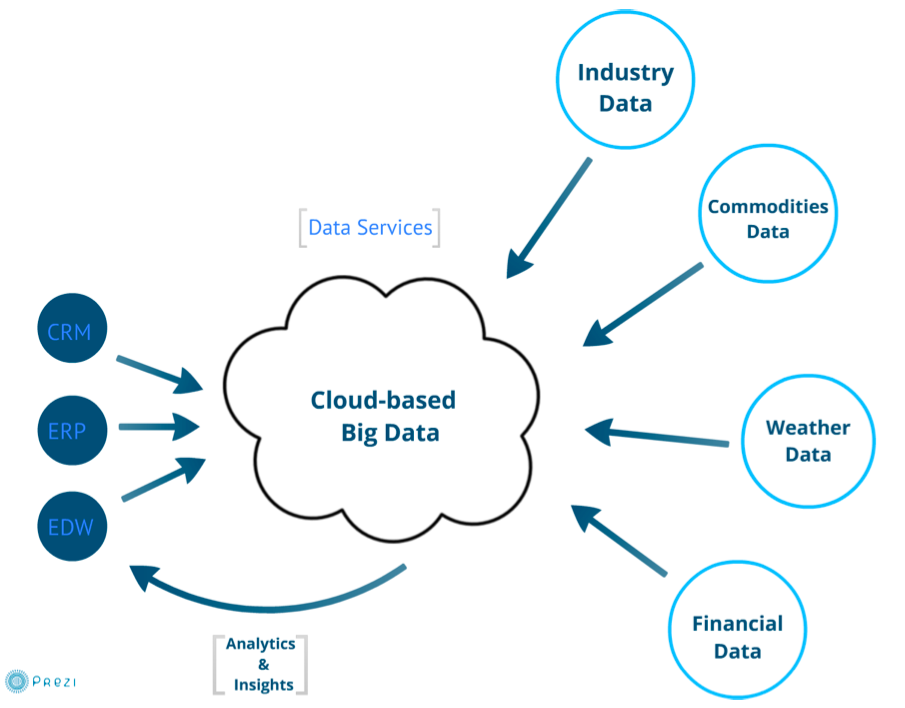
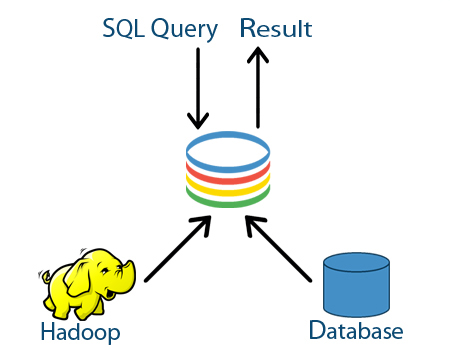
A Isilon defende que a tecnologia pode suportar, com vantagens, um “data lake” para Big Data se a análise de dados for executada dentro do repositório.
 |
| Craig Cotton, |
O fato de, segundo , a análise de dados custar 30 mil dólares por terabyte, usando tecnologia da Teradata e da Oracle, levou a que menos de 1% dos dados existentes fossem analisados com software avançado. Craig Cotton, diretor de marketing de soluções da Isilon, uma empresa da EMC, considera que a utilização da Hadoop baixou muito esses custos, mas traz outros desafios.
No cruzamento e nas correlações de dados, com base em múltiplas fontes, não funciona de forma muito eficaz, defende Craig. Isso esbarra na ideia de colocar as ilhas de dados existentes nas empresas num repositório comum e acessível de várias maneiras: um “data lake”, ou traduzindo literalmente, um “lago de dados”.
É um repositório central onde todos os dados são introduzidos e armazenados na versão original. Os volumes de trabalho dos sistemas de informação da empresa, os de processamento automático pré-agendado, aqueles em tempo real e em interação com as bases de dados, busca empresarial e analítica avançada, vão alimentar-se desse substrato de dados.
A Isilon propõe os seus sistemas de software e hardware para suporte a esse repositório e a projetos de expansão de recursos de armazenamento sobre Network Attached Storage (NAS).
Computerworld ‒ Que problemas tem a Hadoop para a vossa concepção de “data lake”?
Craig Cotton ‒ A Hadoop é muito boa para analisar dados mas só “fala” em HDFS e é necessário retirar os dados do “data lake” por protocolos SMB (Server Message Block) ou NFS (Network File System) ou FTP (File Transfer Protocol). E como se faz o backup de tudo? É muito lento. Na Isilon, estamos a olhar para tecnologias capazes de acelerar tudo isso.
CW ‒ No “data lake”, os dados estão disponíveis para serem analisados sem terem de sair desse repositório?
CC ‒ É a “in-place analytics” [ ou analítica no “sítio” onde estão os dados].
CW ‒ Em que matriz se baseia?
CC ‒ São dados não estruturados, montados no software da Isilon.
CW ‒ E o motor de análise qual será?
CC ‒ Aí está! Uma das vantagens será precisamente a possibilidade de escolher vários. Atualmente, o mais proeminente é a Hadoop. Mas se eu montar um cluster Hadoop, esse sistema só conseguirá comunicar segundo a norma HDFS.
Por isso tenho de usar ferramentas muito lentas que não são nativas para implantar dados, por via de outros protocolos. E se eu tiver 100 terabytes de Big Data e quiser movê-los de um sistema de armazenamento primário para um “cluster” Hadoop, demoro mais de 24 horas numa rede de 10 Gigabits.
CW ‒ E isto pode ser adaptado para novas normas de ferramentas de análise de dados?
CC ‒ Claro. Posso ter uma aplicação Linux e querer analisar os dados por via de NFS. Por isso, além de segurança e suporte a algumas funcionalidades de “multitenancy”, grande expansibilidade e, o mais crítico, é garantir múltiplas formas de acesso.
Depois de ter isso é que posso fazer análises de correlações mesmo interessantes. Podemos ver o caso de uma empresa de cuidados de saúde: tem informação sobre médicos numa base de dados, informação de receitas noutra e pacientes noutra.
Mas assim que os tiver num “date lake”, pode detectar que 90% de determinados pacientes, medicados com determinada combinação de comprimidos, ficou doente.
CW ‒ Como é que a tecnologia da Greenplum pode ser aproveitada neste quadro?
CC ‒ É uma tecnologia de base de dados “in-memory” de alto desempenho
CW ‒ Mas como pode relacionar-se com esta estrutura?
CC ‒ Posso instalar essa base de dados no Isilon, caso queira, ou posso retirar os dados dela e colocá-los no “data lake”. Para fazer as análises, usamos a solução Pivotal HD com motor HAWQ ou Cloudera.
Temos alguns clientes a usarem Pivotal e Cloudera, porque fazem coisas diferentes. Podemos suportar as duas distribuições, ao contrário da Hadoop. Alguns clientes questionam-se sobre se vão precisar de mais de duas. Há 30 anos não se levantava claramente a hipótese de uma organização precisar de mais de uma base de dados, e hoje têm várias e de diversos tipos.
Pensamos que, com o tempo, vai haver necessidade para mais distribuições da Hadoop. E, desta forma que propomos, podem aceder aos mesmos dados desde várias distribuições.
CW ‒ Quais serão os principais desafios de implantação de um “data lake”?
CC ‒ Para obter benefícios reais, embora não preveja que as empresas mudem logo de uma estrutura de silos para o “data lake”, um dos desafios é a necessidade de investir na ideia. Depois deverão evoluir para este tipo de plataforma, à medida que as plataformas instaladas atinjam o fim de vida.
Se houver orçamento, há a capacidade tecnológica e de expansão para desenvolver imediatamente. Mas, de uma forma mais prática, devem começar por um pequeno “data lake” e depois aumentá-lo ao longo do tempo.
Para alguns clientes, mover os dados demoraria três a cinco anos, enquanto para outros seria uma questão de meses.
CW ‒ E também não existe experiência suficiente no mercado para este novo tipo de projeto.
CC ‒ Sim, é verdade, isto envolve uma mudança nos paradigmas, até na implantação e gestão do sistema. Mas uma das vantagens do Isilon para os “data lakes” é poder dar-lhe início com três nós, e depois evoluir para 144 ao longo do tempo, conforme forem precisos mais métodos de acesso, e se acrescentam mais nós de armazenamento.
CW ‒ Que lições tem para partilhar das experiências e projetos já realizados na implantação de um “data lake”?
CC ‒ Várias. Uma é que, como a Hadoop é tradicionalmente usada como tecnologia de armazenamento DAS [de "direct attached storage"], estamos a formar os clientes sobre como usar armazenamento partilhado baseado em NAS.
Achamos que esta tem injustamente uma má reputação, a de ser demasiado lenta para o Hadoop. Na verdade, não é.
Mas supondo que é 10% mais lenta, se forneço com ela resultados 18 horas antes de começar a análise com DAS, é importante que [o processo em absoluto] seja mais lento? Porque deixa de ser preciso transferir os dados, a análise faz-se logo onde estão. E neste processo estamos mais próximos da Cloudera e estamos a desenvolver uma parceria com ela.
CW ‒ Mas o que é que aprenderam sobre este tipo de projetos?
CC ‒ Num grande banco, descobriu-se que havia 18 divisões todas a desenvolverem projetos baseados em analítica. Estavam todas a criar a sua ilha de armazenamento analítico.
Felizmente, o CTO apercebeu-se disso, conseguiu congregar toda a gente na organização e determinar que não iam ter 18 ilhas diferentes. Precisavam de aceder todos aos mesmos dados, e numa organização daquele tipo há requisitos de seguranças mais apertados.
CW ‒ E a montagem de um “data lake” resolveu esse assunto?
CC ‒ Resolveu, mas precisaram de capacidades seguras para haver instâncias utilizadas por múltiplos departamentos, num modelo “multitenant” [na qual a mesma instância serve várias entidades utilizadoras]. Isso é uma coisa que será importante para as grandes organizações.
CW ‒ Outra questão pode ser o licenciamento deste tipo de software. Como lidam com isso?
CC ‒ Não vamos cobrar por protocolos usados, nem pelo Hadoop no Isilon.
CW ‒ Como é que as empresas integram esta visão com aquilo que já têm? Qual é a melhor forma?
CC ‒ Temos quase cinco mil clientes e estamos a encorajá-los a pedirem-nos uma licença gratuita de Hadoop, fornecemos kits de iniciação de Hadoop, com versão para a Pivotal, Cloudera, Apache, Hortonworks, incluindo as extensões VMware para virtualizar a Hadoop. Aos clientes que não têm Isilon propomos o Isilon NFS na Internet para montar uma máquina de virtualização, para testes.
Também temos prestadores de serviço, por exemplo a Rackspace, a oferecer “data lake as a service” – ou seja, como um serviço. Se os clientes decidirem montar isto em cloud computing ou num modelo híbrido, têm essa opção.
CW ‒ Como é que isto se integra com a vossa estratégia de centro de dados definido por software, ou Software Defined Datacenter?
CC ‒ No EMC World, fizemos um anúncio preliminar de que o Isilon estará disponível no próximo ano como solução unicamente de software. Temos os nós S210 e X410, baseados no Intel Ivy bridge, e já são 99% constituídos por hardware “comodity”, já afinados para funcionarem bem com a nossa tecnologia.
O One FS funciona sobre Unix BSD. Vamos suportar plataformas de formato Open Compute e plataformas de hardware ”commodity”.