

Como acontece com qualquer nova tecnologia, as soluções para Big Data Analytics começaram a apresentar sinais de amadurecimento, e isto se reflete numa oferta de mais e melhores opções para analisar os dados das empresas aliando desempenho, usabilidade e segurança.
Analiso a seguir as 8 tendências apontadas pelo CIO.
1 – Big Data Analytics na nuvem

Embora desenvolvido inicialmente para funcionar com clusters de máquinas físicas, o Hadoop evoluiu, e muitos provedores oferecem opções para processamento de dados na nuvem, a exemplo de Amazon (Redshift e Kinesis), Google (Big Query) e IBM (Bluemix).
Há alguma controvérsia sobre os custos de utilizar soluções na nuvem para processar volumes muito grandes de dados (petabytes e acima), mas acredito num ajuste do mercado para que as ofertas de soluções na nuvem sejam atrativas mesmo para cenários mais “agressivos” de análise de dados.
Quando se trata de volumes menores de dados, a nuvem é a melhor opção, pois processar 1 TB de dados pode custar a partir de 25 dólares. Nada mal hein ?

O Hadoop atualmente suporta alternativas ao Map/Reduce, e as versões mais recentes oferecem mais recursos para escalabilidade, desempenho e segurança, além de facilidades que estão tornando cada vez mais simples utilizar as ferramentas, transformando o Hadoop no S.O. para dados “de fato”, o que deve se refletir numa adoção mais acelerada de agora em diante.
Integração com SQL, dados em memória, processamento de streamming, grafos e muitos outros tipos de processamentos de dados já são suportados, tornando a solução genérica o suficiente para ser útil aos mais diversos segmentos de mercado.
3 – Big Data Lakes

Comecei a ver este termo citado com mais frequência na mídia, significando que há um movimento de utilizar o Hadoop como “repositório gigante de dados”, ou seja, as empresas podem simplesmente “despejar” seus dados neste repositório, e construir gradativamente os esquemas necessários para acesso aos dados disponíveis.
Por um lado, isso reduz a necessidade de todo um trabalho prévio de modelagem antes de ser possível analisar os dados. Por outro, exige mais conhecimento para construir esquemas para acesso aos dados à medida que se tornam necessários, sob demanda, num processo incremental.
4 – Mais Análises Preditivas

Com as tecnologias para Big Data, a possibilidade de analisar mais dados implica também na possibilidade de analisar mais atributos, variáveis, metadados e registros, permitindo otimizar as amostras utilizadas em análises estatísticas e aumentando a capacidade de fazer previsões a partir dos dados.
O fato de não ter restrições de poder computacional faz uma diferença muito grande, segundo especialistas, permitindo formular os problemas de maneiras diferentes e viabilizando análises que antes eram impossíveis.
5 – SQL integrado ao Hadoop
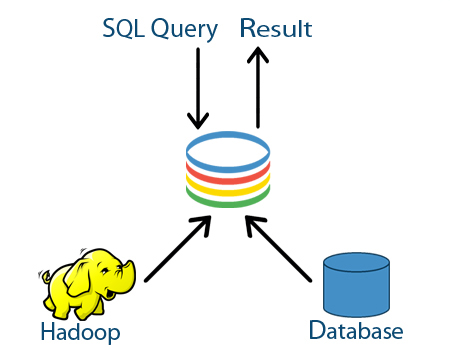
As ferramentas que permitem o suporte à linguagem SQL com Hadoop estão evoluindo muito rapidamente, como todo o ecossistema Big Data, tanto em quantidade quanto qualidade, especialmente desempenho.
Isto é importante porque representa a possibilidade de utilizar uma linguagem que o mercado já conhece, mas dentro de um novo contexto, com novas possibilidades, o que simplifica o uso das novas soluções baseadas em Hadoop, reduzindo o investimento necessário em treinamento, por exemplo.
Embora o Hive continue evoluindo, especialista apontam que alternativas desenvolvidas pela Cloudera, Pivotal, IBM e outros fornecedores oferecem melhor desempenho, facilitando a análise interativa.
6 – Mais e melhores opções NoSQL

NoSQL não é nenhuma novidade pra quem acompanha o blog. Especialistas estimam entre 15 e 20 soluções Open Source NoSQL populares, cada uma com sua especialidade.
Soluções baseadas em grafos que facilitam a análise de redes de relacionamentos, ou especializadas em tratar fluxos de dados (streamming) de sensores ou redes sociais como Twitter, estão sendo integradas ao ecossistema Hadoop.
7 – Deep Learning

A combinação de técnicas de aprendizado de máquina conhecida como Deep Learning e que se baseia em redes neurais está evoluindo, e especialistas apontam grande potencial para a solução de problemas relacionados a negócios.
Identificar relações entre dados, ou destacar aqueles mais relevantes dentre um grande volume de informações são algumas das possibilidades que a técnica oferece, sem a necessidade de modelos especializados ou instruções através de códigos e programação.
Um exemplo muito interessante envolveu a aplicação de um algoritmo de Deep Learning para examinar dados da Wikipedia, tendo como resultado o aprendizado “por conta própria” de que Califórnia e Texas são estados dos EUA.
8 – Analytics em memória

Mas tem gente usando errado, especialistas advertem. Estas soluções não são a melhor opção para lidar com dados que não mudam com frequência ou que não precisam ser analisados de muitas formas diferentes em tempo real. Nesse caso, é um desperdício de dinheiro.
O Spark é uma solução muito promissora que fornece a possibilidade de manipular grandes volumes de dados usando técnicas de armazenamento em memória de maneira análoga ao que o Map/Reduce faz em disco, e assim oferecendo uma alternativa às soluções tradicionais de bancos de dados em memória.
Conclusão
Do que tenho acompanhado, vejo claramente que (nunca antes na história deste planeta :) uma tecnologia foi tão rapidamente assimilada pelo mercado como estas relacionadas ao Big Data.
A evolução das ferramentas e o crescimento do ecossistema Hadoop ocorre na velocidade da luz, trazendo cada vez mais facilidades para uso da tecnologia pelas empresas.
Por isso, entendo que o recado é muito claro: a hora de começar a aprender, experimentar e adotar a tecnologia é agora, pois em breve o Hadoop vai virar commodity, e a vantagem competitiva para o profissional de TI que busque uma carreira nesta área desaparecerá.
Do ponto de vista das organizações, entendo que é hora de planejar iniciativas para 2015 que contemplem a utilização da tecnologia, e sugiro começar utilizando soluções mais simples de implementar, seja através de uma máquina virtual da Cloudera ou com o serviço EMR da Amazon.
Website: http://nitrotv.w.pw
Fonte : http://portal.comunique-se.com.br

Nenhum comentário:
Postar um comentário